
Diskussionen om att välja en data lake eller ett data warehouse (datalager) är förmodligen bara i sin linda. De viktigaste skillnaderna i struktur, syfte, användning och generell smidighet gör båda modellerna unika. Beroende på företagets behov är valet av lösning viktigt för att skapa tillväxt.
Data lake och data warehouse (datalager) används båda i stor utsträckning i samband med lagring av mycket data, men de är inte desamma. En data lake är en stor ”pool” av rådata, där syftet med data ännu inte har definierats. Ett datalager är ett arkiv med strukturerade, filtrerade data som redan har bearbetats för ett specifikt ändamål.
De två begreppen blandas ofta ihop, men i verkligheten är det mycket mer som skiljer de åt än som liknar. Faktum är att den enda verkliga likheten mellan dem är datalagring på hög nivå.
4 viktiga skillnader mellan data lake och data warehouse
Det finns flera skillnader mellan ett datalager och en data lakes. Datastruktur, användare, tillgängligheten och det övergripande syftet med data.
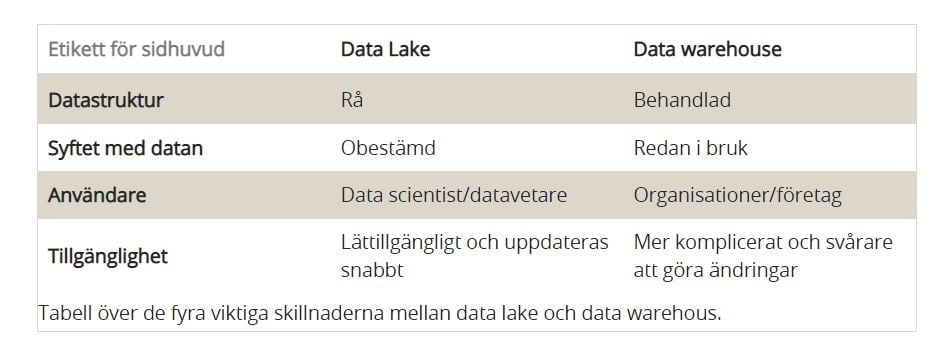
Datastruktur: rådata vs behandlad
Den kanske största skillnaden mellan data lakes och datalager är strukturen för hur data lagras, rå kontra bearbetade data. Data lakes lagrar främst rå och obearbetad data, medan i ett datalager lagras bearbetad och förädlad data.
På Grund av detta så kräver data lakes vanligtvis mycket större lagringskapacitet än ett datalager. Fördelen med rådata är att det är data som snabbare kan anpassas för att analyseras olika ändamål och är idealisk för maskininlärning. Nackdelen med rådata är dock att data lakes ibland blir som en träsk av data med dålig datakvalitet och användningsmöjligheter.
Datalager, som bara lagrar bearbetade data, sparar värdefullt lagringsutrymme genom att inte behålla data som aldrig kan användas. Dessutom kan bearbetade data lätt förstås av en bredare publik.
Syfte: obestämd vs i bruk
Syftet med enskilda dataflöden i en data lake är inte bestämt i förväg. Rå data flödar in i ett ”hav”, ibland med tanke på en specifik framtida användning och ibland bara för att få in det. Detta innebär att data lakes är avsevärt mindre organiserade och har mindre datafiltrering än den datalager.
Bearbetade data är rådata som har transformerats för en specifik användning. Eftersom datalager bara innehåller bearbetade data används oftast all data för ett specifikt syfte i organisationen. Detta innebär att lagringsutrymme inte går till spillo på data som aldrig kan användas.
Användare: data scientist/datavetare vs organisationer/företag
Data lakes är ofta svåra att navigera för dem som inte känner till eller är vana med rådata. Rå, ostrukturerad data kräver därför vanligtvis en data scientist samt specialiserade verktyg för att förstå och översätta data för att kunna användas av organisationen..
Bearbetade data används i skapandet av analys så som diagram, kalkylblad, tabeller och mycket mer så att de flesta, om inte alla, anställda i ett företag kan använda det. Bearbetade data, till exempel de som lagras i ett datalager, kräver bara att användaren känner till ämnet som representeras i data.
Tillgänglighet: flexibel vs säker
Tillgänglighet och användarvänlighet avser användningen av datalagret som helhet, inte själva data i lagret. Data lake-arkitekturen har ingen struktur och är därför lättillgänglig och lätt att ändra. Dessutom kan alla ändringar som görs i data göras snabbt eftersom data lakes har mycket få begränsningar.
Datalager är utformat för att vara mer strukturerat. En stor fördel med datalager-arkitektur är att bearbetning och struktur av data gör själva datan lättare att analysera. Strukturens begränsningar gör datalagret svårt och dyrt att manipulera.
Läs även vår blogg: Data lake-arkitektur – [best practice]
Vad är rätt för mig?
Datadrivna organisationer behöver ofta båda. Data lakes uppstår från ett behov av att använda big data och dra nytta av rådata och ostrukturerade data för maskininlärning, men då det fortfarande finns ett behov av att lagra data för analytisk användning av affärsanvändare så behövs datalager. Nedan listar vi några exempel på olika användningsområden.
Hälso- och sjukvård: Data lakes lagrar ostrukturerad information
Inom hälso- och sjukvård har man i många år använt datalager, men det har aldrig varit helt framgångsrikt. På grund av den ostrukturerade karaktären av data inom sjukvården (medicinska anteckningar, kliniska data, etc.) och behovet av insikt i realtid är datalager i allmänhet inte en idealisk modell. Data lakes tillåter där en kombination av strukturerad och ostrukturerad data, som tenderar att vara bättre lämpad inom hälso- och sjukvård.
Utbildningssektorn: Data lakes erbjuder flexibla lösningar
Under de senaste åren har värdet av big data i utbildningssektorn blivit mycket tydligt. Betygsdata, närvaro och så vidare kan inte bara hjälpa elever som inte lyckas komma tillbaka på rätt spår, utan kan faktiskt hjälpa till att förutsäga potentiella problem innan de uppstår. Flexibla data lakes har dessutom hjälpt utbildningsinstitutioner att effektivisera fakturering, förbättra insamlingar och så vidare.
Denna typ av data är oftast enorm och väldigt rå, ofta tjänar lärosäten inom utbildningssektorn mest på flexibilitet hos data lakes.
Finanssektorn: Datalager tilltalar massorna
Inom ekonomi är ett datalager ofta den bästa lagringsmodellen. Detta beror på att denna modell kan struktureras och ge åtkomst för hela företaget istället för bara en datavetare. Big data har hjälpt finanssektorn att göra stora framsteg, och datalagring har varit en avgörande faktor i dessa framsteg.


